深入了解以太坊虚拟机是一个系列的文章,本文是第3篇,本系列其他部分的译文链接在文章结尾处

Solidity提供了在其他编程语言常见的数据类型。除了简单的值类型比如数字和结构体,还有一些其他数据类型,随着数据的增加可以进行动态扩展的动态类型。动态类型的3大类:
- 映射(Mappings):
mapping(bytes32 => uint256),mapping(address => string)等等 - 数组(Arrays):
[]uint256,[]byte等等 - 字节数组(Byte arrays):只有两种类型:
string,bytes
在本系列的第二篇文章中我们看见了固定大小的简单类型在内存中的表示方式。
- 基本数值:
uint256,byte等等 - 定长数组:
[10]uint8,[32]byte,bytes32 - 组合了上面类型的结构体
固定大小的存储变量都是尽可能的打包成32字节的块然后依次存放在存储器中的。(如果这看起来很陌生,请阅读本系列的第二篇文章: 固定长度数据类型的表示方法
在本文中我们将会研究Solidity是如何支持更加复杂的数据结构的。在表面上看可能Solidity中的数组和映射比较熟悉,但是从它们的实现方式来看在本质上却有着不同的性能特征。
我们会从映射开始,这是三者当中最简单的。数组和字节数组其实就是拥有更加高级特征的映射。
映射
让我们存储一个数值在uint256 => uint256映射中:1
2
3
4
5
6
7pragma solidity ^0.4.11;
contract C {
mapping(uint256 => uint256) items;
function C() {
items[0xC0FEFE] = 0x42;
}
}
编译:1
solc --bin --asm --optimize c-mapping.sol
汇编代码:1
2
3
4
5
6
7
8
9
10
11
12
13tag_2:
// 不做任何事情,应该会被优化掉
0xc0fefe
0x0
swap1
dup2
mstore
0x20
mstore
// 将0x42 存储在地址0x798...187c上
0x42
0x79826054ee948a209ff4a6c9064d7398508d2c1909a392f899d301c6d232187c
sstore
我们可以将EVM想成一个键-值( key-value)数据库,不过每个key都限制为32字节。与其直接使用key0xC0FEFE,不如使用key的哈希值0x798...187c,并且0x42存储在这里。哈希函数使用的是keccak256(SHA256)函数。
在这个例子中我们没有看见keccak256指令本身,因为优化器已经提前计算了结果并內联到了字节码中。在没什么作用的mstore指令中,我们依然可以看到计算的痕迹。
计算地址
使用一些Python代码来把0xC0FEFE哈希成0x798...187c。如果你想要跟着做下去,你需要安装Python 3.6,或者安装pysha3 来获得keccak_256哈希函数。
定义两个协助函数:1
2
3
4
5
6
7
8import binascii
import sha3
#将数值转换成32字节数组
def bytes32(i):
return binascii.unhexlify('%064x' % i)
# 计算32字节数组的 keccak256 哈希值
def keccak256(x):
return sha3.keccak_256(x).hexdigest()
将数值转换成32个字节:1
2
3
4>>> bytes32(1)
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01'
>>> bytes32(0xC0FEFE)
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xc0\xfe\xfe'
使用+操作符,将两个字节数组连接起来:1
2>>> bytes32(1) + bytes32(2)
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x02'
计算一些字节的 keccak256 哈希值:1
2>>> keccak256(bytes(1))
'bc36789e7a1e281436464229828f817d6612f7b477d66591ff96a9e064bcc98a'
现在我们可以计算0x798...187c了。
存储变量items的位置是0x0(因为它是第一个存储变量)。连接key0xc0fefe和items的位置来获取地址:1
2
3# key = 0xC0FEFE, position = 0
>>> keccak256(bytes32(0xC0FEFE) + bytes32(0))
'79826054ee948a209ff4a6c9064d7398508d2c1909a392f899d301c6d232187c'
为key计算存储地址的公式是:1
keccak256(bytes32(key) + bytes32(position))
两个映射
我们先把公式放在这里,后面数值存储时需要计算会用到该公式。
假设我们的合约有两个映射:1
2
3
4
5
6
7
8
9pragma solidity ^0.4.11;
contract C {
mapping(uint256 => uint256) itemsA;
mapping(uint256 => uint256) itemsB;
function C() {
itemsA[0xAAAA] = 0xAAAA;
itemsB[0xBBBB] = 0xBBBB;
}
}
itemsA的位置是0,key为0xAAAA:1
2
3# key = 0xAAAA, position = 0
>>> keccak256(bytes32(0xAAAA) + bytes32(0))
'839613f731613c3a2f728362760f939c8004b5d9066154aab51d6dadf74733f3'itemsB的位置为1,key为0xBBBB:1
2
3# key = 0xBBBB, position = 1
>>> keccak256(bytes32(0xBBBB) + bytes32(1))
'34cb23340a4263c995af18b23d9f53b67ff379ccaa3a91b75007b010c489d395'
用编译器来验证一下这些计算:1
$ solc --bin --asm --optimize c-mapping-2.sol
汇编代码:1
2
3
4
5
6
7
8tag_2:
// ... 忽略可能会被优化掉的内存操作
0xaaaa
0x839613f731613c3a2f728362760f939c8004b5d9066154aab51d6dadf74733f3
sstore
0xbbbb
0x34cb23340a4263c995af18b23d9f53b67ff379ccaa3a91b75007b010c489d395
sstore
跟期望的结果一样。
汇编代码中的KECCAK256
编译器可以提前计算key的地址是因为相关的值是常量。如果key使用的是变量,那么哈希就必须要在汇编代码中完成。现在我们无效化优化器,来看看在汇编代码中哈希是如何完成的。
事实证明很容易就能让优化器无效,只要引入一个间接的虚变量i:1
2
3
4
5
6
7
8
9pragma solidity ^0.4.11;
contract C {
mapping(uint256 => uint256) items;
//这个变量会造成常量的优化失败
uint256 i = 0xC0FEFE;
function C() {
items[i] = 0x42;
}
}
变量items的位置依然是0x0,所以我们应该期待地址与之前是一样的。
加上优化选项进行编译,但是这次不会提前计算哈希值:1
$ solc --bin --asm --optimize c-mapping--no-constant-folding.sol
注释的汇编代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45tag_2:
// 加载`i` 到栈中
sload(0x1)
[0xC0FEFE]
// 将key`0xC0FEFE`存放在内存中的0x0位置上,为哈希做准备
0x0
[0x0 0xC0FEFE]
swap1
[0xC0FEFE 0x0]
dup2
[0x0 0xC0FEFE 0x0]
mstore
[0x0]
memory: {
0x00 => 0xC0FEFE
}
// 将位置 `0x0` 存储在内存中的 0x20 (32)位置上,为哈希做准备
0x20 // 32
[0x20 0x0]
dup2
[0x0 0x20 0x0]
swap1
[0x20 0x0 0x0]
mstore
[0x0]
memory: {
0x00 => 0xC0FEFE
0x20 => 0x0
}
// 从第0个字节开始,哈希在内存中接下来的0x40(64)个字节
0x40 // 64
[0x40 0x0]
swap1
[0x0 0x40]
keccak256
[0x798...187c]
// 将0x42 存储在计算的地址上
0x42
[0x42 0x798...187c]
swap1
[0x798...187c 0x42]
sstore
store: {
0x798...187c => 0x42
}
mstore指令写入32个字节到内存中。内存操作便宜很多,只需要3 gas就可以读取和写入。前半部分的汇编代码就是通过将key和位置加载到相邻的内存块中来进行“连接”的:1
2 0 31 32 63
[ key (32 bytes) ][ position (32 bytes) ]
然后keccak256指令哈希内存中的数据。成本取决于被哈希的数据有多少:
- 每个SHA3操作需要支付 30 gas
- 每个32字节的字需要支付 6 gas
对于一个uint256类型key,gas的成本是42:30 + 6 * 2。
映射大数值
每个存储槽只能存储32字节。如果我们尝试存储一个更大一点的结构体会怎么样?1
2
3
4
5
6
7
8
9
10
11
12
13
14pragma solidity ^0.4.11;
contract C {
mapping(uint256 => Tuple) tuples;
struct Tuple {
uint256 a;
uint256 b;
uint256 c;
}
function C() {
tuples[0x1].a = 0x1A;
tuples[0x1].b = 0x1B;
tuples[0x1].c = 0x1C;
}
}
编译,你会看见3个sstore指令:1
2
3
4
5
6
7
8
9
10
11tag_2:
//忽略未优化的代码
0x1a
0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7d
sstore
0x1b
0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7e
sstore
0x1c
0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7f
sstore
注意计算的地址除了最后一个数字其他都是一样的。Tulp结构体成员是依次排列的(..7d, ..7e, ..7f)。
映射不会打包
考虑到映射的设计方式,每项需要的最小存储空间是32字节,即使你实际只需要存储1个字节:1
2
3
4
5
6
7
8pragma solidity ^0.4.11;
contract C {
mapping(uint256 => uint8) items;
function C() {
items[0xA] = 0xAA;
items[0xB] = 0xBB;
}
}
如果一个数值大于32字节,那么你需要的存储空间会以32字节依次增加。
动态数组是映射的升级
在典型语言中,数组只是连续存储在内存中一系列相同类型的元素。假设你有一个包含100个uint8类型的元素数组,那么这就会占用100个字节的内存。这种模式的话,将整个数组加载到CPU的缓存中然后循环遍历每个元素会便宜一点。
对于大多数语言而言,数组比映射都会便宜一些。不过在Solidity中,数组是更加昂贵的映射。数组里面的元素会按照顺序排列在存储器中:1
2
3
40x290d...e563
0x290d...e564
0x290d...e565
0x290d...e566
但是请记住,对于这些存储槽的每次访问实际上就像数据库中的key-value的查找一样。访问一个数组的元素跟访问一个映射的元素是没什么区别的。
思考一下[]uint256类型,它本质上与mapping(uint256 => uint256)是一样的,只不过后者多了一点特征,让它看起去就像数组一样。
length表示一共有多少个元素- 边界检查。当读取或写入时索引值大于
length就会报错 - 比映射更加复杂的存储打包行为
- 当数组变小时,自动清除未使用的存储槽
bytes和string的特殊优化让短数组(小于32字节)存储更加高效
简单数组
看一下保存3个元素的数组:1
2
3
4
5
6
7
8
9
10// c-darray.sol
pragma solidity ^0.4.11;
contract C {
uint256[] chunks;
function C() {
chunks.push(0xAA);
chunks.push(0xBB);
chunks.push(0xCC);
}
}
数组访问的汇编代码难以追踪,使用Remix调试器来运行合约: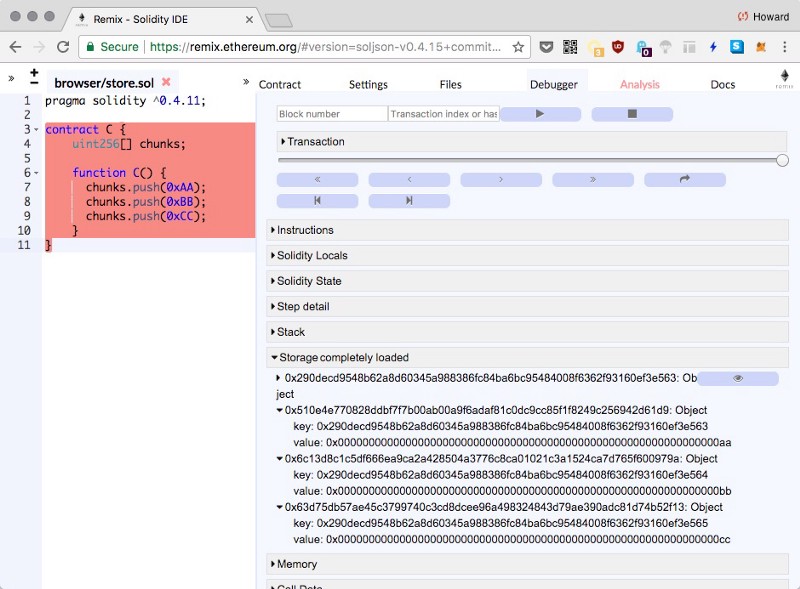
模拟的最后,我们可以看到有4个存储槽被使用了:1
2
3
4
5
6
7
8key: 0x0000000000000000000000000000000000000000000000000000000000000000
value: 0x0000000000000000000000000000000000000000000000000000000000000003
key: 0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563
value: 0x00000000000000000000000000000000000000000000000000000000000000aa
key: 0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e564
value: 0x00000000000000000000000000000000000000000000000000000000000000bb
key: 0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e565
value: 0x00000000000000000000000000000000000000000000000000000000000000cc
chunks变量的位置是0x0,用来存储数组的长度(0x3),哈希变量的位置来找到存储数组数据的地址:1
2
3# position = 0
>>> keccak256(bytes32(0))
'290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563'
在这个地址上数组的每个元素依次排列(0x29..63,0x29..64,0x29..65)。
动态数据打包
所有重要的打包行为是什么样的?数组与映射比较,数组的一个优势就是打包。拥有4个元素的uint128[]数组元素刚刚好需要2个存储槽(再加1个存储槽用来存储长度)。
思考一下:1
2
3
4
5
6
7
8
9
10
11pragma solidity ^0.4.11;
contract C {
uint128[] s;
function C() {
s.length = 4;
s[0] = 0xAA;
s[1] = 0xBB;
s[2] = 0xCC;
s[3] = 0xDD;
}
}
在Remix中运行这个代码,存储器的最后看起来像这样:1
2
3
4
5
6key: 0x0000000000000000000000000000000000000000000000000000000000000000
value: 0x0000000000000000000000000000000000000000000000000000000000000004
key: 0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563
value: 0x000000000000000000000000000000bb000000000000000000000000000000aa
key: 0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e564
value: 0x000000000000000000000000000000dd000000000000000000000000000000cc
只有三个存储槽被使用了,跟预料的一样。长度再次存储在存储变量的0x0位置上。4个元素被打包放入两个独立的存储槽中。该数组的开始地址是变量位置的哈希值:1
2
3# position = 0
>>> keccak256(bytes32(0))
'290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563'
现在的地址是每两个数组元素增加一次,看起来很好!
但是汇编代码本身优化的并不好。因为使用了两个存储槽,所以我们会希望优化器使用两个sstore指令来完成任务。不幸的是,由于边界检查(和一些其他因素),所以没有办法将sstore指令优化掉。
使用4个sstore指令才能完成任务:1
2
3
4
5
6
7
8/* "c-bytes--sstore-optimize-fail.sol":105:116 s[0] = 0xAA */
sstore
/* "c-bytes--sstore-optimize-fail.sol":126:137 s[1] = 0xBB */
sstore
/* "c-bytes--sstore-optimize-fail.sol":147:158 s[2] = 0xCC */
sstore
/* "c-bytes--sstore-optimize-fail.sol":168:179 s[3] = 0xDD */
sstore
字节数组和字符串
bytes和string是为字节和字符进行优化的特殊数组类型。如果数组的长度小于31字节,只需要1个存储槽来存储整个数组。长一点的字节数组跟正常数组的表示方式差不多。
看看短一点的字节数组:1
2
3
4
5
6
7
8
9
10// c-bytes--long.sol
pragma solidity ^0.4.11;
contract C {
bytes s;
function C() {
s.push(0xAA);
s.push(0xBB);
s.push(0xCC);
}
}
因为数组只有3个字节(小于31字节),所以它只占用1个存储槽。在Remix中运行,存储看起来如下:1
2key: 0x0000000000000000000000000000000000000000000000000000000000000000
value: 0xaabbcc0000000000000000000000000000000000000000000000000000000006
数据0xaabbcc...从左到右的进行存储。后面的0是空数据。最后的0x06字节是数组的编码长度。公式是长度=编码长度/2,在这个例子中实际长度是6/2=3。
string与bytes的原理一模一样。
长字节数组
如果数据的长度大于31字节,字节数组就跟[]byte一样。来看一下长度为128字节的字节数组:1
2
3
4
5
6
7
8
9
10
11
12// c-bytes--long.sol
pragma solidity ^0.4.11;
contract C {
bytes s;
function C() {
s.length = 32 * 4;
s[31] = 0x1;
s[63] = 0x2;
s[95] = 0x3;
s[127] = 0x4;
}
}
在Remix中运行,可以看见使用了4个存储槽:1
2
3
4
5
6
7
8
9
100x0000...0000
0x0000...0101
0x290d...e563
0x0000...0001
0x290d...e564
0x0000...0002
0x290d...e565
0x0000...0003
0x290d...e566
0x0000...0004
0x0的存储槽不再用来存储数据,整个存储槽现在存储编码的数组长度。要获得实际长度,使用长度=(编码长度-1)/2公式。在这个例子中长度是(0x101 - 1)/2=128。实际的字节被保存在0x290d...e563,并且存储槽是连续的。
字节数组的汇编代码相当多。除了正常的边界检查和数组恢复大小等,它还需要对长度进行编码/解码,以及注意长字节数组和短字节数组之间的转换。
为什么要编码长度?因为编码之后,可以很容易的测试出来字节数组是长还是短。注意对于长数组而言编码长度总是奇数,而短数组的编码长度总是偶数。汇编代码只需要查看一下最后一位是否为0,为0就是偶数(短数组),非0就是奇数(长数组)。
总结
查看Solidity编译器的内部工作,可以看见熟悉的数据结构例如映射和数组与传统编程语言完全不同。
概括:
- 数组跟映射一样,非高效
- 比映射的汇编代码更加复杂
- 小类型(
byte,uint8,string)时存储比映射高效 - 汇编代码优化的不是很好。即使是打包,每个任务都会有一个
sstore指令
EVM的存储器就是一个键值数据库,跟git很像。如果你改变了任一东西,根节点的校验和也会改变。如果两个根节点拥有相同的校验和,存储的数据就能保证是一样的。
为了体会Solidity和EVM的奇特,可以想象一下在git仓库里数组里面的每个元素都是它自己的文件。当你改变数组里一个元素的值,实际上就相当于创建了一个提交。当你迭代一个数组时,你不能一次性的加载整个数组,你必须要到仓库中进行查找并分别找到每个文件。
不仅仅这样,每个文件都限制到32字节!因为我们需要将数据结构都分割成32字节的块,Solidity编译器的所有逻辑和优化都是很负责的,全部在汇编的时候完成。
不过32字节的限制是完全任意的。支持键值存储的可以使用key来存储任意类型的数值。也许未来我们添加新的EVM指令使用key来存储任意的字节数组。
不过现在,EVM存储器就是一个伪装成32字节数组的键值数据库。
可以看看ArrayUtils::resizeDynamicArray 来了解一下当恢复数组大小时编译器的动作。正常情况下数据结构都会作为语言的标准库来完成的,但是在Solidity中嵌入到了编译器里面。
本系列文章其他部分译文链接:
翻译作者: 许莉
原文地址:Diving Into The Ethereum VM Part Three