原文作者是Jameson Lopp,他是BitGo的工程师,也是statoshi.info的创造者以及bitcoinsig.com的建立者。Lopp对于“移除比特币区块大小的限制是安全的,取而代之可以依靠现有的SPV方式”的声明做了一个深入的思考。
翻译作者:许莉
原文地址:Could SPV Support a Billion Bitcoin Users?
一个新的声明被永载在比特币扩展讨论中。
我们听到取消比特币块大小的限制是安全的,因为比特币可以很容易就扩展到巨大的块(指块的大小),然后通过现已存在的简化支付认证( SPV)的方式可以支持数十亿的比特币用户。假设,SPV由于只要求SPV客户存储,发送,以及接收很少的数据而具有非常好的可扩展性。
让我们深入的从多个不同角度来考察一下这个问题。
SPV是如何工作的?
即使是直到两年后 Mike Hearn创造了BitcoinJ 时才开始实施SPV,但Satoshi在比特币白皮书 中早就描述了SPV的高层设计。
以下引用于比特币白皮书中:
8.简易支付认证(Simplified Payment Verification)
认证支付有可能是不需要遍历整个网络全部节点的。用户只需要保存一份最长的工作量证明链的区块头内容就可以了(通过不停的向网络节点查询直到自己认为已经获取到了最长的链),以及获取带有时间戳的区块的交易相关的Merkle树分支。用户无法自己检测交易,但是通过链接到链中的某个位置,用户可以看到网络节点已经接受了这笔交易,并在进一步确认网络已经接受后块就会被加入进去。
因此,只要诚实节点掌控网络,那么这个认证就是可靠的,但是如果网络被攻击者所制服,认证就会变得非常的脆弱。当网络节点可以自己认证交易时,只要攻击者能够持续掌控网络,则简易方法可能会被攻击者捏造的交易所欺骗。有一个策略可以保护不被攻击者欺骗,那就是当检测到一个无效区块时接受网络节点的改变,提示用户的软件下载完整区块和改变交易以确认一致性。经常接收到付款的业务可能还是希望能有一个自己的节点,来保证更加独立的安全性和更加快速的认证。
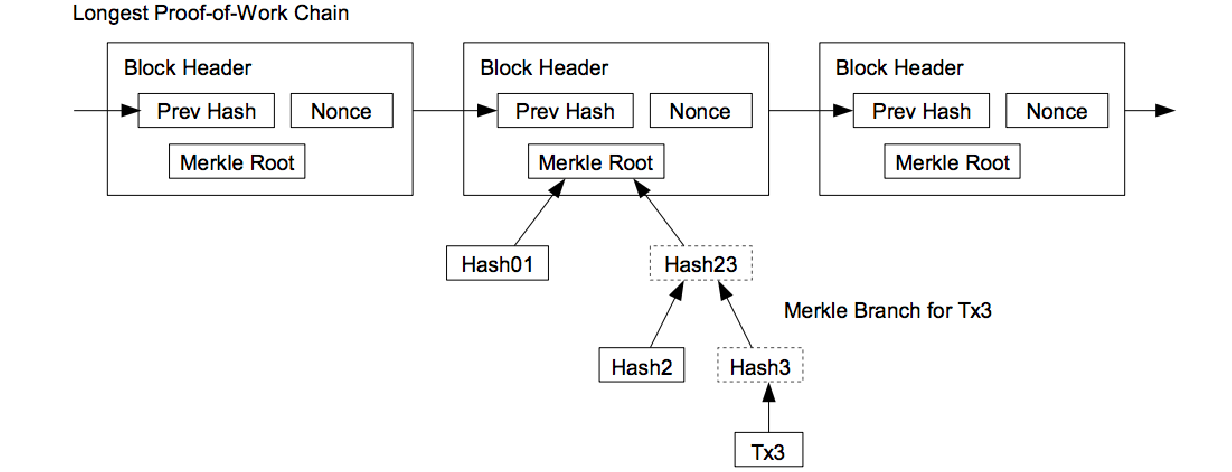
初期SPV的实现是非常简单的—下载整个的区块链,在宽带方面下载整个的区块链并没有比下载完整块(交易已满的块)更高效。
通过丢弃与SPV客户钱包无关的交易,才能够节省大量的磁盘空间。BIP 37 花了18个月的时间才发布,为交易提供了Bloom过滤规范,因此依靠区块头的Merkle根可以显示区块中的交易内容,就如Satoshi描述的那样。提供Bloom过滤规范大大的降低了贷款的使用。
当SPV客户与比特币网络同步时,他会连接一个或多个全面认证的比特币节点,确定链顶端的最新一个区块,然后使用‘getheaders’命令请求所有的区块头,从最后一个他同步到链顶端的区块开始。
如果SPV客户只对与钱包相应的特定交易感兴趣,那么它会基于钱包拥有私钥的所有地址构建一个Bloom过滤器,然后发送‘filterload’命令给全节点(一个或多个全节点),全节点就会按照过滤要求发送给客户所需的交易。
在同步区块头和可能加载Bloom过滤器之后,SPV客户会发送一个‘getdata’命令来请求从他们上次在线时所遗漏的每个区块(可能是过滤之后的),按照顺序来获取遗漏的每个区块。
当客户同步完之后,如果他还保持着连接全节点对端的状态,那么它只会接收到符合Bloom过滤器交易的‘inv’清单信息。
SPV客户端扩展
从客户的视角来看,当使用最小的CPU资源,带宽,和磁盘空间时,Bloom过滤是在区块链中获取相关交易最高效的方法。
每个比特币的区块头只有80个字节,所以在区块链整个8年多的历史中只有38兆的数据被写入。每年(粗略有52,560个区块),不管区块链中区块的大小,仅仅只添加了4.2兆的数据。
用来显示区块中交易内容的Merkle树也扩展的非常好。因为新添加到树中的每‘层’都可以让树能表示‘叶子’的总数翻一番。即使是在一个含有数百万交易的区块中,你也不需要一个很深的树来紧凑的显示交易内容。
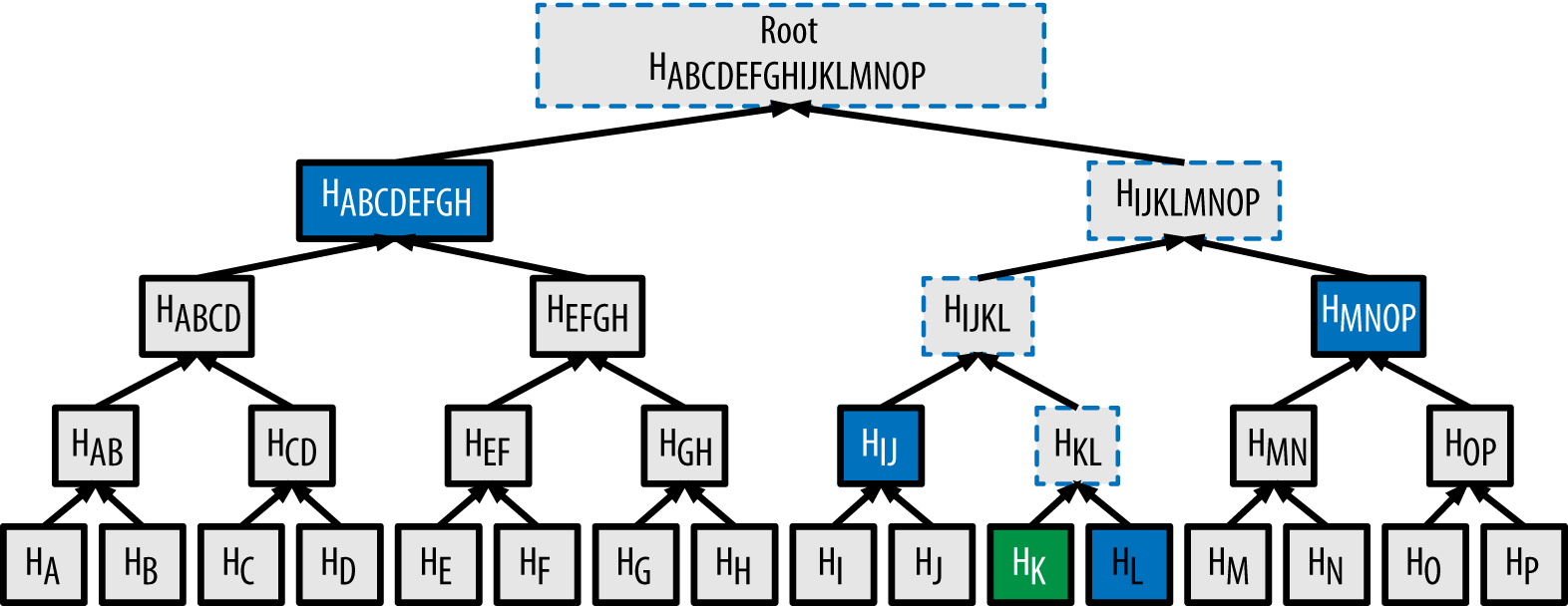
Merkle树的数据结构是非常高效的,深度为24的树就能表示出1600万的交易——这足以代表一个8GB的区块。然而,这种交易的Merkle树证明大小仍然保持在1KB以下。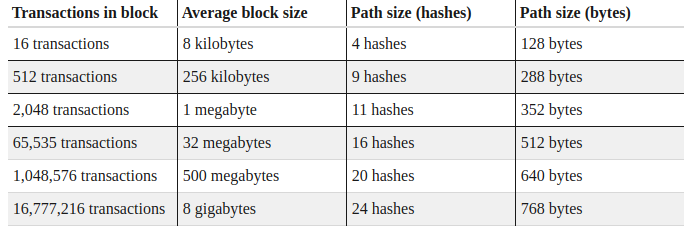
从SPV客户角度来看,这是非常清晰的,比特币网络可以扩展到千兆大小的区块而SPV客户端处理所需要的那些少量数据也是没有任何问题的——即使是一个3G网络的移动手机。
但是啊,扩展比特币网络不是那么简单的事情!
SPV服务端扩展
当SPV对客户端非常高效的时候,对于服务端却没这么好了——也就是,对于SPV客户发送请求的全节点,由于几种原因,这种方法表现出非常差的可扩展性。
网络中的节点必须要处理非常庞大的数据才能返回一个对端想要的数据,而且需要为每个区块中的每个发送请求的对端进行着这重复的过程。磁盘I/O很快就变成了一个瓶颈。
每个SPV客户都必须从上次与网络联系之后开始同步整个区块链,或者它认为自己遗漏了某些交易,它必须要从建立钱包日期起开始重新扫描整个区块链。最坏的情况下,在写入数据时,能达到大约150GB。全节点必须要从磁盘加载每个区块,根据客户要求来过滤并返回结果。
由于区块链是个追加模式的账簿,数量就会不停的增加。没有一个广泛协议的改变,区块链裁剪与BIP 37就无法兼容——它期待所有的区块对于广发NODE_BLOOM消息的全节点都是可获取的。
通过遗漏的方式就可以欺骗BIP 37 SPV客户端。为了预防这个,SPV客户端连接多个节点(通常是4个 ),不过这并不能作为担保——Sybil攻击可以将SPV客户端从主网络分离。这将全节点的网络负载增加 4倍。
对于每个已同步到区块链顶端的SPV客户端,每个传入块和交易都必须被单独过滤。这就涉及到无法忽略的CPU时间量,而且必须给每个连接的SPV客户单独完成。
推测一下数量
在写入的时候大约有8,300个接收传入连接的全节点在运行,其中8,000个全节点广播NODE_BLOOM消息,因此有能力对于SPV客户的请求做出响应。但是,当前数量下的监听全节点能够合理支持多少SPV客户端呢?
让网络由能够支撑日用户量达到数万亿以及区块大到能够容纳数万亿用户交易的全节点组成,需要什么?
比特币内核默认传入连接最大值为117,这在网络上可以创建上线为936,000个可使用的套接字。然而,这些大多数套接字在今天都已经被消耗完了。
每个全节点默认连接8个其他的全节点。比特币内核开发者Luke-Jr的节点计数 (非常粗略的)估计在写入的时候有 100,000个总节点数。其中92,000个节点不为SPV客户端提供有效套接字。这让全节点就消耗了800,000个有效套接字,为SPV客户端仅仅留下了136,000个有效套接字。
这让我总结出大概有85%的有效套接字都是被网络中的全节点网格给消耗掉了。(值得注意的是,Luke-Jr的估计方法无法计算出非监听节点在线的时间,当然,其中一些节点肯定是周期性的断开连接然后又重新建立连接)。
从statoshi.info 中获取的平均值为100个全节点(8传出连接,92个传入连接)对端和25个SPV客户。这也就是80%的有效套接字被全节点给消耗掉了。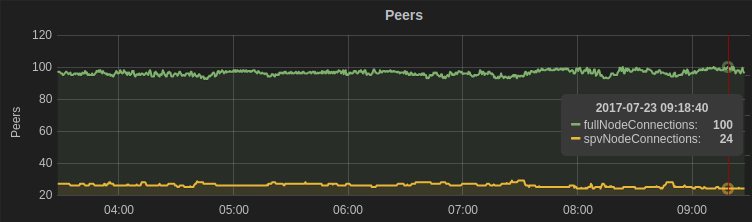
如果我们想要甚至10亿的SPV客户都可以使用这个系统,那就必须要有足够的全节点资源可以服务这些客户——网络套接字,CUP周期,磁盘I/O等等。我们能实现这个目标吗?
为了相信SPV扩展能够做到,我们就比较保守的假设10亿的SPV的每个用户:
- 每天接受和发送一条交易
- 每天将钱包同步到区块链顶端一次
- 同步的时候查询四个节点以降低因遗漏而被欺骗
每天10亿的交易,如果平均分配(当然不会被平均分配)每个区块会有7百万的交易。由于Merkle树非常好的可扩展性,只需要23个哈希值就能证明此种区块中的交易内容:736个字节的数据外加每个交易的平均500个字节。
每天加上另外的12KB的区块头数据,SPV客户会依然每天还是使用大概20KB的数据。
然而,每天10亿的交易会产生大概500GB的区块链数据让全节点去存储以及处理。SPV客户连接上之后要查询自己钱包前一天的交易时,四个节点各自都需要读取和过滤这500GB的数据。
记住在 8,000个SPV服务全节点的网络中当前大约有 136,000个有效套接字是为了SPV客户端准备的。如果每个SPV客户端使用4个套接字,那么在任何时刻只有34,000个客户端可以与网络进行同步。如果一次性在线的人数大于34,000,当其他的用户打开钱包试图与区块链顶端进行同步的时候就会接受到连接错误。
因此,在当前只能支撑34,000个用户在任意时刻能进行同步的网络上,要支撑10亿的SPV用户每天同步一次,也就是一天有29,400个组的用户必须要连接、同步、断开连接:每个用户必须要能够在3秒钟之内完成前一天数据的同步。
这就会造成一点难题,因为它要求每个全节点要有能力连续的每秒为每个SPV客户读取以及过滤167GB的数据。在一个全节点对应20个SPV客户端时,也就意味着每秒需要处理3,333GB的数据。我还不知道有任何的设备能拥有这样的吞吐量。不过应该可以创建一个巨大的RAID 0阵列的高端固态磁盘 ,每个磁盘可以实现大约每秒600MB的吞吐量。
你大概需要 5,555个这样的设备来达到目标吞吐量。这种磁盘写入时会花费400美元,它拥有大约1TB的容量——足够保这种存理论网络上2天的区块数据。因此,每两天你就需要一个新的磁盘阵列,也就是每两天大概需要花费超过220万美元——这意味着保存1年的区块数据并达到所要求的吞吐量需要花费超过1亿美元。
当然,我们可以利用假设来稍稍调整这些数字,我们是否可以假设出一个节点的花费能够合理一点的场景?
让我们来尝试一下:
如果我们有 100,000个全节点都运行在更加便宜,大容量的旋转磁盘上,然后我们能以某种方式让这些全节点全部都接收SPV客户,而且设法更改全节点的软件让它能支持1,000个连接的SPV客户。
这样我们就拥有1亿个套接字可供SPV客户使用,能够支持2500万的SPV客户同时在线(每个客户需要4个套接字)。因此每个SPV客户每天拥有2,160秒来与网络同步数据。如果让一个全节点能满足要求,那么需要它能够保持着每个SPV客户读取速度达到231MB/s,也就意味着 1,000 个连接的SPV客户速度就要达到 231GB/s。
一个 7,200 RPM的硬盘读取速度大概是220MB/s,所以大概 1,000多个RAID 0阵列设备就能达到目标读取速度。
在写入的时候你可以购买一个价值$400的10TB容量设备 ,因此一个400,000美元的这些设备RAID阵列就能够保存20天的区块数据——也就是需要720万美元来保存1年的数据并达到要求的读取吞吐量,这个价格相对就比较容易让人接受了。
差不多每天就要至少添加两个这样的设备!
值得注意的是,没人会在头脑清醒的时候用那么多设备来运行RAID 0阵列,因为如果其中一个设备有问题那么整个磁盘都会崩溃。因此具有容错功能的RAID阵列将更加昂贵并且性能更差一些。而且这看起来也是令人难以置信的乐观——100,000个组织愿意每年花费数百万的美元来运行全节点。
另外一个需要注意的是,这些保守的估计中,都是假设SPV客户能够通过某种方式来协调,以便在每一天内均匀分配其同步时间。而现实中,会有每天和每周的周期性峰值和活跃性低谷——网络会需要一个比估计值合理的高点的容量来满足峰值时要求。
否则的话,在使用高峰时SPV客户同步会失败。
有趣的是,原来改变每个节点的套接字数不会影响任何给定的全节点总负载量——它还是需要处理相同数量的数据。在这个等式中真正重要的是全节点与SPV客户的比例,当然还有全节点需要处理的链中区块的大小。
最终结果似乎是不可避免的:运行能够支持每天10亿链上交易者的SPV的全节点的花费是非常庞大的。
寻找一个中间点
通过这一点,可以清楚的看到,每天10亿的交易量让运行全认证节点的花费除了最有钱的人之外没人能负担的起。
但是,如果我们略过这些计算,取而代之尝试寻找一个公式,可以通过增加链上交易的吞吐量来确定增加网络负载的费用呢?
为了让比特币网络能够每秒支持目标交易量(增加了86,400个新日常用户的容量),我们可以计算每个节点磁盘吞吐量要求如下:
这提供了全节点服务SPV客户需求的每秒最小磁盘读取吞吐量。根据现在已存在的网络特性和可用的技术,我们可以通过将磁盘吞吐量作为假设的瓶颈来推算节点运行花销的估计值。当然这里肯定也会存在其他资源限制因素,来增加全节点运行的花销。
接下来的运算 中,我使用了这些假设:
- 根据statoshi.info 交易平均大小字节数 = 500 bytes
- SPV用户的总数 = 每天每笔交易1个
- 被SPV客户端消耗的套接字 =标准为5
- 全节点对SPV客户可获取的套接字的数量 = 之前计算的数字是136,000
- 硬盘吞吐量和空间的花销 = $400 10TB, 7,200 PRM的RAID 0配置硬盘
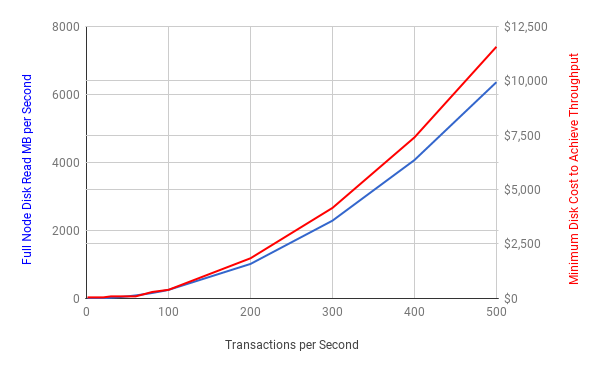
我们可以看见在正常情况下磁盘的吞吐量还是比较合理的,但是当每秒超过100个交易的时候就不合理了。在这个点的时候你就需要购买多个磁盘,并且将其分段在RAID阵列中以达到要求的性能。
不幸的是,磁盘吞吐量的需求以及因此全节点的运行成本相对于每秒交易数量的二次增加。花销很快就变得大多数人无法承担。
作为参考,请记住Visa每秒大约处理2,000笔交易。在比特币中这大概需要将近$200,000价值的磁盘来跟上SPV的需求。值得注意一点是,这些图表保持着全节点的数量在一个8,000的常量—在现实中,他们很有可能随着花销的增加而减少,因此增加了吞吐量的需求以及运行剩下的节点花销会增加的更快。
这似乎是中心化节点的复合限制。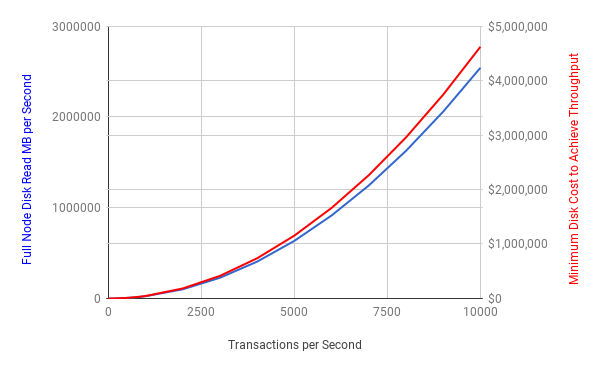
就像我在如何从中心化中拯救比特币的节点网络 中总结的,其中一个关于增加区块大小的根本争论问题是节点的运行成本。上面的计算让我们对于计算节点运行成本的复杂有了基本的认识,计算复杂是因为涉及了太多的变量—上面的计算是基本上让变量都保持一个常量而且只关注磁盘I/O的花销。
一年前我做的民意调查(不是非常科学)显示98%的节点运营商每月不会支付超过$100来运行一个节点,即使他们对比特币的投资非常高昂。我愿意打赌,如果增加比特币链上交易一个数量级将会导致失去大多数的全节点,如果增加两个数量级会导致失去90%的节点甚至更多。
我相信,假设只有少数人会愿意为了运行一个全节点而不怕麻烦的去建立一个RAID陈列会安全一点。如果在这种情况下,声称这样的增加对于普通用户而言没关系是站不住脚的,因为这将会导致甚至没有足够的全节点磁盘吞吐量或套接字来为SPV提供服务。
SPV其他的缺点
SPV对于安全性或全认证节点隐私性没有要求的终端用户而言是非常好的。然而,有很多原因可以被认为是多数SPV网络节点的阻碍者,不论它的可扩展性如何。
SPV做出主要的假设,导致其具有比全认证节点的安全性和隐私性更加的薄弱。
- SPV用户相信矿工会正确认证和加强比特币规则,他们认为具有最大累积工作量证明的块链也是一个有效的链。你可以从这篇文章 中了解SPV和全节点安全模型的不同。
- SPV用户认为全节点不会因为遗漏对他们撒谎。全节点不会撒谎说一个其实不存在在区块上的交易是存在的,但是可以撒谎说存在在区块上的交易没有发生。
- 因为SPV客户力求效率,所以他们只发送请求来获取属于他们自己交易的数据。这导致失去大量的隐私。
有趣的是,BIP 37的合著者 Matt Corallo, 后悔创建了它
”现在在系统中用户隐私的最大问题就是 BIP37 SPV bloom过滤器。我很抱歉,我写了这个。”
BIP 37 Bloom过滤的SPV客户基本上是没有隐私的 ,即使使用不合理地高 false-positive rates。Jonas Nick(Blockstream的安全工程师)发现给出一个公钥,他可以确定给出钱包70%的其他地址。
你可以通过在多个对端中分开Bloom过滤器来解决SPV的恶劣隐私,虽然这会让SPV的扩展性比在全节点上放更多的负载还要差。
BIP 37 对于微不足道的拒绝服务攻击也同样脆弱。展示的代码可以在这里获取 ,它通过发送很多快速库存请求经过特殊构造的过滤器,导致磁盘不停的查找以及CPU的高使用率来让全节点瘫痪。
攻击的概念证明作者和主要开发者的Peter Todd解释:
”根本问题是你可以用很少的网络带宽来消耗不成比例的磁盘I/O带宽。“
甚至直到今天,Satoshi在白皮书中描述的欺诈警告还是没有实现。实际上,这方面的努力调查显示它甚至不可能实现一个轻量级的欺诈警告。
例如,欺诈警告只有当你真的获得了被要求证明是欺诈的数据才有效—如果矿工不提供那个数据,欺诈警告就不会被创建。再比如,SPV客户没有Satoshi设想的安全级别。
从一个高层次的角度来看,一个由大多数SPV节点组成的世界可以让共识改变比如coin cap的总数或甚至让编辑分类账本更加的容易。更少的全认证节点意味着更多的中心化共识规则实施,因此更少的阻力改变共识规则。有人些人认为这是一个特征,但是更多的人认为这是个缺陷。
潜在的改进
SPV安全性和可扩展性有可能会通过好几种方法被潜在的改进,比如通过欺诈证明,欺诈提示,输入证明,花费证明等等方式。但是就我所知,这些都还只存在与概念阶段,还没有准备好开始开发产品。
Bloom过滤器承诺 可以提高隐私性,但是在过滤器的大小和它的 false positive rate 存在着一个效能的权衡: 太粗略意味着对端会下载太多的 false-positive 区块,而太精细又意味着过滤器对于任何使用SPV客户来下载的人来说太巨大又不切实际。
它会减少全节点磁盘吞吐量的负载,但是权衡就变成了SPV客户和全节点之间增加的带宽,因为整个区块会在网络上进行传送。
最近提出的紧凑客户端过滤 消除了隐私的问题,但是它要求如果匹配过滤器全节点就需要下载整个区块(虽然不一定非要通过p2p网络)。
UTXO承诺 可以让SPV客户同步他们当前的UTXO集,因此钱包余额就不需要去请求全节点来扫描整个区块链。相反,它可以提供现有UTXOs的证明。
也许可以通过要求SPV客户要么提交工作量证明(站不住脚的电池供电设备比如手机),要么基于通道的微型支付(如果客户还没接收到钱那么就不可能会自举)来防范Bloom过滤器的Dos攻击,但是这两者都没有提出直接的解决方案。
全节点的磁盘读取需求可能会通过改进数据索引和批量处理SPV客户的请求等多种方式进行减少。
Ryan X Charles在下面的评论中指出,使用BIP70的支付协议来直接告诉别人你发送给他们的UTXO支付ID,可以移除他们对Bloom过滤器使用的需要,因为他们可以直接从全节点来请求数据。如果你愿意接受隐私权衡的话,这是非常高效的。
照我说,这还有很多的改进空间—为了改进链上的扩展性还有很多的困难需要克服。
合适的扩展解决方案
如果我们忽略扩展区块大小的其他众多杂项问题,比如块传播延迟,UTXO集扩展,初始化区块同步时间和安全性以及隐私等权衡问题,只要有人愿意投资巨大的资源来开发改进软件和运行需求的基本设备,那么技术上是有可能将比特币扩展到每天亿万的链上用户。
不过比特币似乎不太可能以这种方式有机的演变,因为有其他很多有校的方式来扩展系统。最高效的扩展形式已经被使用了:联合中心化API提供者。当使用这个方法的时候,倾向于存在巨大的信任和隐私权衡,但是很多交互涉及到合同协议,这也降低了一些危险性。
用不可靠的方式进行扩展,诸如闪电之类的2层协议提供了更高效的扩展,因为大量的数据传输,仅仅只需要在直接涉及到给定链下交易的少数方之间进行。你可以把它想成广播到所有以太网通信层与路由IP层之间的区别—互联网在没有路由的情况下无法扩展,货币网络也如此。
虽然这种扩展方法比传统中心化扩展在技术上要复杂很多而且还需要克服很多独特的挑战, 为调研和这些路由协议开发的前期投资在长期来看会带来巨大的收益,因为他们在数量级上减少了整个网络需要承载的负载。
两者之间还有很多可以探索:
我仍然相信 长期来看, 比特币还是需要大一点的区块。
让我们耐心一点,策略性的在保持安全性和隐私的同时尝试将系统扩展到尽可能的高效。
一个可审计的,轻去中心化的PayPal如果站在普通用户的立场上运作那么肯定能起作用,但是它就不会提供比特币现在所喜爱的财务主权。
感谢 Matt Corallo, Mark Erhardt and Peter Todd为本文提供的审查和反馈。
信息披露:CoinDesk是Digital Currency Group的子公司,拥有Blockstream所有权。